

Days 4 and 5 of the Statistics 10-day challenge (HackerRank) were dedicated to specific probability distributions. Day 6 builds on this, particularly on the normal distribution, and is dedicated to the Central Limit Theorem (CLT).
This is the main reason why the normal distribution is so widely used. That is because it shows that this distribution can be used to analyse a huge variety of problems, even though their underlying probability distribution is not normal.
Without being too formal, the CLT states that when a random variable is the result of the sum of a large number of identically distributed distributions, then its own distribution will converge to the normal one.
The Normal Distribution is characterized by two parameters: the mean and the standard deviation. These can be computed from the underlying distribution, and the formula is given by the CLT.
Let 
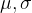
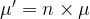
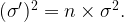
This is powerful stuff, and the exercises in this section show how it can be applied.
Task
A large elevator can transport a maximum of 9800 pounds. Suppose a load of cargo containing 49 boxes must be transported via the elevator. The box weight of this type of cargo follows a distribution with a mean of 205 pounds and a standard deviation of 15 pounds. Based on this information, what is the probability that all 49 boxes can be safely loaded into the freight elevator and transported?
I like to analyse this problem from the top, and see how then I can solve it with what I have. The random variable here is the total weight of the 49 boxes. It is the sum of the weight of each individual box, but that in turn is another random variable (first clue). Besides, the weights of all boxes follow the same distribution (second clue).
If we could somehow describe this total weight by a specific distribution W, then we could answer the problem simply by computing ![\Pr[W \leq 9800]](https://s0.wp.com/latex.php?latex=%5CPr%5BW+%5Cleq+9800%5D&bg=ffffff&fg=000&s=1&c=20201002)
But.. did you notice the two clues above? This is a sum of identically distributed random variables, and so we can apply the Central Limit Theorem.
Notice that we don’t know anything else about this particular distribution. For all we care, it can have a really strange shape very far from a nice bell-figure. But neither does the CLT require anything about it. It does not mandate the underlying distribution to be of any specific type, only that it has a finite variance. And this matches that.
All this tells us is that the distribution W can be approximated by a normal distribution with
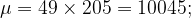
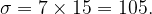
And the program will be similar to those of Day 5.
import math from utils import Utils from stats import Stats mean = 205 * 49 stdDev = 15 * math.sqrt(49) pLessThan9800 = Stats.normDistCumulative(mean, stdDev, 9800) print( Utils.scale (pLessThan9800, 4))
Task
The number of tickets purchased by each student for the University X vs. University Y football game follows a distribution that has a mean of 2.4 and a standard deviation of 2.0.
A few hours before the game starts, 100 eager students line up to purchase last-minute tickets. If there are only 250 tickets left, what is the probability that all 100 students will be able to purchase tickets?
This problem is very similar to the previous one, so I will only outline it briefly and then present the code.
The random variable (T) is the total number of tickets requested, again a sum of n = 100 copies of the same distribution. We don’t even have to compute the parameters of the new distribution, we can let the program do that. The problem’s question is the probability that the variable T takes a value up to 250:
![\Pr[T \leq 250].](https://s0.wp.com/latex.php?latex=%5CPr%5BT+%5Cleq+250%5D.&bg=ffffff&fg=000&s=1&c=20201002)
The answer is given by the following code.
import math from utils import Utils from stats import Stats mean = 2.4 * 100 stdDev = 2.0 * math.sqrt(100) pSuccess = Stats.normDistCumulative(mean, stdDev, 250) print( Utils.scale (pSuccess, 4)
Task
You have a sample of 100 values from a population with mean 500 and with standard deviation 80. Compute the interval that covers the middle 95% of the distribution of the sample mean; in other words, compute A and B such that P(A < x < B) = 0.95. Use the value of z = 1.96. Note that z is the z-score.
After the gentle two previous problems, this really looks like an outlier. And at first, it may even be hard to understand what the questioner wants, or how to approach the solution.
One thing is clear: we are using the CLT and can easily compute the parameters for the random variable’s distribution. Now, for the question itself. We want to know the limits A and B that bound the central part of the chart that corresponds to 95% of the whole area. It is important to remember that the normal distribution is symmetric, and in the default one (which is also the one we’re using the symmetry axis coincides with the y-axis. Therefore, A and B are at equal distances of the y-axis, which allows us to transform the original question into this:
![\Pr[x \leq A] = 2.5%](https://s0.wp.com/latex.php?latex=%5CPr%5Bx+%5Cleq+A%5D+%3D+2.5%25&bg=ffffff&fg=000&s=1&c=20201002)
![\Pr[x \geq B] = 2.5%](https://s0.wp.com/latex.php?latex=%5CPr%5Bx+%5Cgeq+B%5D+%3D+2.5%25&bg=ffffff&fg=000&s=1&c=20201002)
![\Pr[x \leq B] = 97.5%](https://s0.wp.com/latex.php?latex=%5CPr%5Bx+%5Cleq+B%5D+%3D+97.5%25&bg=ffffff&fg=000&s=1&c=20201002)
This is the inverse of our usual question.
The tutorial in HackerRank gives no clue on how to solve this, though, except from a link to Wikipedia and an indication of a z-score to use.
What it means is this: The general shape of a normal distribution is dictated by its standard deviation: it can be thinner (smaller values) or wider (larger values). It can also be centered more to the right or to the left of the x-axis. The maximum, and the axis of symmetry, falls exactly on the line 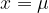
The probability that the random variable (say X) takes a value less than a value x is related to how many standard deviations fall in the interval between x and the mean. For example:
For 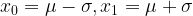
![\Pr[X \leq x_0] = \Pr[X \geq x_1] \simeq 16\%.](https://s0.wp.com/latex.php?latex=%5CPr%5BX+%5Cleq+x_0%5D+%3D+%5CPr%5BX+%5Cgeq+x_1%5D+%5Csimeq+16%5C%25.&bg=ffffff&fg=000&s=1&c=20201002)
For 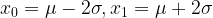
![\Pr[X \leq x_0] = \Pr[X \geq x_1] \simeq 2.3\%.](https://s0.wp.com/latex.php?latex=%5CPr%5BX+%5Cleq+x_0%5D+%3D+%5CPr%5BX+%5Cgeq+x_1%5D+%5Csimeq+2.3%5C%25.&bg=ffffff&fg=000&s=1&c=20201002)
And for 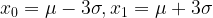
![\Pr[X \leq x_0] = \Pr[X \geq x_1] \simeq 0.13\%.](https://s0.wp.com/latex.php?latex=%5CPr%5BX+%5Cleq+x_0%5D+%3D+%5CPr%5BX+%5Cgeq+x_1%5D+%5Csimeq+0.13%5C%25.&bg=ffffff&fg=000&s=1&c=20201002)
Now, the z-score is exactly this factor that I applied to 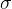
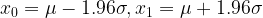
![\Pr[X \leq x_0] = \Pr[X \geq x_1] \simeq 2.5\%](https://s0.wp.com/latex.php?latex=%5CPr%5BX+%5Cleq+x_0%5D+%3D+%5CPr%5BX+%5Cgeq+x_1%5D+%5Csimeq+2.5%5C%25&bg=ffffff&fg=000&s=1&c=20201002)
The problem statement asks for a specific distribution: _the mean of 100 values taken from a specific distribution_. The mean is simply the sum divided by their count.
Represent by 
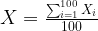
The mean of a random variable, also called “expected value” and often denoted by E[.], is linear. This means that to compute the mean of a sum of variables we can sum their means. And to compute the mean of a scaled variable, we can just multiply the scaling factor by the mean of the base variable.
In this case, that gives
![E[X] = E\left[ 1/100 \cdot \sum_{i=1}^{100} X_i \right] = 1/100 \cdot \sum_{i=1}^{100} E[X_i] = \mu](https://s0.wp.com/latex.php?latex=E%5BX%5D+%3D+E%5Cleft%5B+1%2F100+%5Ccdot+%5Csum_%7Bi%3D1%7D%5E%7B100%7D+X_i+%5Cright%5D+%3D+1%2F100+%5Ccdot+%5Csum_%7Bi%3D1%7D%5E%7B100%7D+E%5BX_i%5D+%3D+%5Cmu&bg=ffffff&fg=000&s=1&c=20201002)
There are also equivalent properties for variance (which is the square of the standard deviation). If two variables are independent, the variance of their sum is the sum of their variances. And the variance of a scaled variable is the square of the scaling factor times the variance of the base variable. This gives:
![Var[X] = Var \left[ \frac{\sum_{i=1}^{100} X_i}{100} \right] = \frac{ \sum_{i=1}^{100} Var[X_i]}{100^2} = \frac{\sigma^2}{100}.](https://s0.wp.com/latex.php?latex=Var%5BX%5D+%3D+Var+%5Cleft%5B+%5Cfrac%7B%5Csum_%7Bi%3D1%7D%5E%7B100%7D+X_i%7D%7B100%7D+%5Cright%5D+%3D+%5Cfrac%7B+%5Csum_%7Bi%3D1%7D%5E%7B100%7D+Var%5BX_i%5D%7D%7B100%5E2%7D+%3D+%5Cfrac%7B%5Csigma%5E2%7D%7B100%7D.&bg=ffffff&fg=000&s=1&c=20201002)
This gives 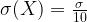
Now we can compute A and B with:
A = 500 – 1.96 * 8
B = 500 + 1.96 * 8
The code is here:
import math from utils import Utils baseMean = 500 baseStdDev = 80 n = 100 mean = baseMean stdDev = baseStdDev / math.sqrt(n) z = 1.96 A = mean - z * stdDev B = mean + z * stdDev print( Utils.scale (A, 2)) print( Utils.scale (B, 2))
This is it, and this time there was no need to add new functions to the Stats class.
Full code available here, commit 6857eb3.