

In the previous post, I described list comprehensions and how we can use them to replace the Map and Filter functions.
In this post, I’ll continue with the Weighted Mean example, and talk about the Reduce function.
The function sum, which I used in the solution to the weighted mean problem, is an example of an aggregation function (in SQL parlance): it sums all the elements of a list. Since sum is an associative binary operation, summing a list is done by processing it pairwise: the first two elements are summed and its result placed in a value we call an accummulator. Then, the next value in the list is added to the accummulator (which accummulates the result of operating on all the elements one by one) and so on until the list is exhausted. There are cases in which a sum function is not enough. Other popular aggregation functions are Product, Average, Count, Min and Max.
In the general case, we will not have an aggregation function ready for our use, but we can make use of the reduce function to create one. This will allow us to represent a very general kind of for loop in a functional style. But before I show how that can be done, I want to do some preparatory explanation and introduce the notion of anonymous function.
In Python, the function reduce is available in the module functools and can be imported with
from functools import reduce
It takes 3 arguments: a summarizing function, a sequence, and an optional initializer. It “reduces” the sequence to a single value that summarizes it. The function must be binary, where the leftmost argument represents the accummulated value, and the rightmost value is the next element to be taken from the sequence and absorbed into the result. If it is also associative, then the result will be unambiguous. That means that the reduction of the sequence to a single value by successive application of the function will have the same value no matter which pairs we choose to process first. If the function were not associative, then processing the list from the first pair on the left moving to the right could have a different result than processing it from the first pair on right moving to the left. For example, addition is associative but subtraction is not.
14, 7, 10, 3 = (((14+7) + 10) + 3) = (14 + (7 + (10 + 3)))
but
14, 7, 10, 3 != (((14-7) - 10) - 3) = (14 - (7 - (10 - 3)))
For a more dramatic example, try exponentiation, even in a case where commutativity doesn’t matter:
((((2^2)^2)^2)^2) = 65536 (2^(2^(2^(2^2)))) = 2^65536
Python is not ambiguous, it always applies the function from left to right, but if you decide to apply a non-associative function, at least be sure that there is an intuitive meaning for that. For example, if your function is subtraction, then reducing from left to right would be like reducing a balance with a series of withdrawals, and indeed it does not make sense to think of the subtraction in the other direction. But exponentiation becomes something else entirely when reduced from right to left, more akin to a power tower function, which is still entirely reasonable. Someone not familiar with the order of computation in Python’s reduce may have doubts over the final result.
The initial value of the accummulator can be specified by passing a third argument. If this is not present, then the accummulator will be initialized to the function of the first value in the sequence.
Just like filter and map, reduce is a facilitator of a functional-programming style. Python is still an eminently imperative language: you list commands one after the other, which are executed in sequence. But like many modern languages (like JavaScript and C#) it includes features that make a functional-style possible. In a functional language, a program is just a long expression: every computation is the result of applying a composition of functions to an input. This is a radical difference to the dominant imperative paradigm in the last decades (although it is currently losing ground) but it is actually the first programming style.
A fundamental building block of such languages are functions that allow us to iterate an operation over some structure. That is the clear purpose of map, and filter can be seen as applying a predicate over a structure and getting a list of the successes so it can be seen as a disguised kind of map. Reduce also iterates over a structure, but acts like a bridge between the vector and the scalar world, transforming a sequence into a single value.
For example, we can compute the sum of the squares of a sequence like this:
from functools import reduce def square(x): return x**2 def sumSquare(a,x): return a + square(x) def sumSquares(X): return reduce(sumSquare, X, 0)
Another fundamental building block is the concept of anonymous function. In Python, these are constructed using the lambda operator. By using anonymous functions, we can write the same reduce above but without having to previously defined square or sumSquare, which is very convenient if they are not used anywhere else. For example, this is equivalent to the above code:
from functools import reduce
def sumSquares(X):
return reduce(lambda a,x:a + x**2, X, 0)
You may be wondering at this strange name and where it comes from. As far as I can tell, it comes from LISP, the grand-mummy of all functional languages. In LISP, this allowed us to define anonymous functions, that could be passed around like any other kind of argument. This is the hallmark of functional programming languages, the capacity to treat a function like a first class value. But even this is not the first use of the word. LISP took its concept from 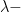
A function is defined by the literal 
And just for an example of how this works:
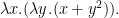

It is exactly this structure that LISP, and later Python, emulate with its lambda operator.
And since the emulation is rather close, I’ll limit the examples to Python from now on.
The purpose of lambda is to be able to write anonymous, light-weight functions. This is good, for example, for locality. There are many situations where we want to use a function in just one place, and never again. We could define it at the top level, and then pass that as argument, but creating an anonymous function that does the same (if the function is short) makes the program easier to read (the function is defined where it is used) and to debug, by keeping the code close to where it is used and freeing the reader from scrolling back and forth between the definition and the application of the function.
The Python version of the example above is this:
f = lambda x,y: x + y**2 f(10,5)
The function in the body of the lambda operator can be much more sophisticated, but has to be a single expression (in pure functionaly stye).
Not surprisingly, lambda functions are very used with the functional constructions I’ve listed above, since they all require a function argument.
And that brings me to yet another implementation of the weighted mean:
def weightedMean(X, W):
return (reduce(
lambda a,t: a + t[0] * t[1],
zip(X,W),
0
) /
sum(W)
)
We could go further and make the whole computation inside the reduce function. Maybe you shouldn’t, because the result is not as clear, but if you wanted to, just for fun, here it is how.
In the above, we sum all weighted contributions of the sequence; after all values are summed, we divide by the total weights. We can do the same in a stream-like fashion: every time we add a contribution to the sequence, we compute the mean by dividing by the total weight obtained thus far. The next time, we have to restore the previous sum, add the new term and divide by the new weight. For example, if we have the sequences [1,2,3,4,5,6], [3,2,1,1,2,3], after 3 contributions we have:
Current sum: 10 Current weight: 6 Weighted mean: 1.67
The next contribution is 4 * 1, leading to this state:
Current sum: 14 Current weight: 7 Weighted mean: 2
To pass from the previous state to the new one, we have to do:
(1.67 * 6 # restore the old sum
+ 4) # add new contribution
/ (6+1) # divide by new weight
In code, we must keep a state holding the current sum and the current weight. Then, we do something like this:
def weightedMean2(X,W):
return (reduce(
lambda (acc_sum, acc_wt), (x,w):
(
(acc_sum * acc_wt + x * wt)/(acc_wt + wt),
acc_wt + wt
),
zip(X,W),
(0,0)
)
)
Unfortunately, this is no longer legal code in Python 3. I have used the trick of tuple unpacking in the lambda declaration. In Python, when a function returns a tuple, you can automatically assign each element of a tuple to a different variable like this:
list = [(1,170,65), (2, 198, 102), (3, 154, 72)] (sn, wt, ht) = list[2] # sn = 3, wt = 154, ht = 72
This is called tuple unpacking and is one of the niftiest features of Python. You used to be able to do the same in a lambda function: where you have to declare an argument, if this were a tuple you could list its structure instead, and the tuple elements would be mapped to the corresponding variables. Regrettably, Python 3 has removed this possibility and instead requires you to use indices to access each element of the tuple, and so the above code becomes this:
def weightedMean2(X,W):
return (reduce(
lambda a, t:
(
( a[0] * a[1] + t[0] * t[1])/(a[1] + t[1]),
a[1] + t[1]
),
zip(X,W),
(0,0)
)
)
This is it for today, I hope you have enjoyed this little detour through functional programming in Python. I would love to hear your comments, and of other examples you may think interesting. Meanwhile, stay tuned for the next post.